Elon-Mood Part 2: N-Grams and Graphs
Last time we did some basic data exploration of tweets from Elon Musk. This time we’ll do something slightly more powerful, and we’ll make some pretty(ish) graphs of the data processing we do.
After removing stopwords (low-content common words like a, the, and, etc.):
from nltk.corpus import stopwords as nltk_stopwords
stopwords = set(nltk_stopwords.words('english'))
unstopped = [[t for t in tokenized_datum if t not in stopwords] for tokenized_datum in tqdm(tokenized_data)]
print("\n".join([str(x) for x in unstopped[:5]]))
Our data looked like this:
['@MeltingIce', 'Assuming', 'max', 'acceleration', '2', '3', "g's", ',', 'comfortable', 'direction', '.', 'Will', 'feel', 'like', 'mild', 'moder', '?', 'https://t.co/fpjmEgrHfC']
['@bigajm', 'Yup', ':)']
['Part', '2', 'https://t.co/8Fvu57muhM']
['Fly', 'places', 'Earth', '30', 'mins', 'anywhere', '60', '.', 'Cost', 'per', 'seat', '?', 'https://t.co/dGYDdGttYd']
['BFR', 'take', 'anywhere', 'Earth', 'less', '60', 'mins', 'https://t.co/HWt9BZ1FI9']
And our list of most common words looked like this:
. 2116
, 1091
? 348
Tesla 266
! 246
I 220
& 176
Model 164
( 162
) 154
like 113
S 104
... 101
: 100
good 99
rocket 94
Will 92
3 89
car 84
/ 80
There are some things we expect there, like Tesla and rocket and other things that
obviously relate to Elon’s areas of interest/ventures. But the punctuation is pretty useless
as far as I’m concerned, so let’s deal with that.
Python has a list of punctuation in the string module, so let’s just use that instead of reinventing the wheel.
import string
unstopped_and_depunct = [[t for t in unstopped_datum if t not in string.punctuation] for unstopped_datum in tqdm(unstopped)]
print("\n".join([str(x) for x in unstopped_and_depunct[:5]]))
['@MeltingIce', 'Assuming', 'max', 'acceleration', '2', '3', "g's", 'comfortable', 'direction', 'Will', 'feel', 'like', 'mild', 'moder', 'https://t.co/fpjmEgrHfC']
['@bigajm', 'Yup', ':)']
['Part', '2', 'https://t.co/8Fvu57muhM']
['Fly', 'places', 'Earth', '30', 'mins', 'anywhere', '60', 'Cost', 'per', 'seat', 'https://t.co/dGYDdGttYd']
['BFR', 'take', 'anywhere', 'Earth', 'less', '60', 'mins', 'https://t.co/HWt9BZ1FI9']
Okay, our data now just has words (and numbers, which are just as important as we’ll see later). So now our list of most common words looks like this:
Tesla 266
I 220
Model 164
like 113
S 104
... 101
good 99
rocket 94
Will 92
3 89
car 84
Falcon 80
The 80
launch 79
We 78
next 75
:) 70
Just 67
time 67
would 66
That looks way better. I’m more interested in the content words (nouns, verbs) than the stopwords or the punctuation. Maybe later I’ll add punctuation back into the mix because it has some pragmatic value to indicate the “tone” of the post or something like that, but right now I just want to know what he’s posting about.
One other thing I notice is that something like “S” is a very common word by itself, and I think probably that’s because Elon is talking about the Tesla Model S. To check that, I’m going to run this same analysis, but this time I’m going to use n-grams instead of just single words.
NLTK has an ngrams module, so let’s use that. Yes, it’s mostly trivial to get these ourselves, but I always try to use things other people have built whenever possible.
from collections import Counter
from nltk.util import ngrams
ns = [1,2,3]
nGramFreqs = {}
for n in ns:
nGramFreqs[n] = Counter()
This is just initializing our ngram counters and defining which values of N we are interested in. In my experience, trigrams are usually the best balance of utility and calculation complexity. 4-grams are rarely worth the extra computation they take, and 5-grams are just silly. (please contradict me - I love being wrong)
for tweet in unstopped_and_depunct:
for n in ns:
grams = ngrams(tweet, n)
for gram in grams:
nGramFreqs[n][gram] += 1
Above is where we actually count our n-gram frequencies.
And finally let’s see what we’ve got.
for n in ns:
print("Most common %d-grams:" % n)
for entry, count in nGramFreqs[n].most_common(20):
print(" ".join(entry) + "\t" + str(count))
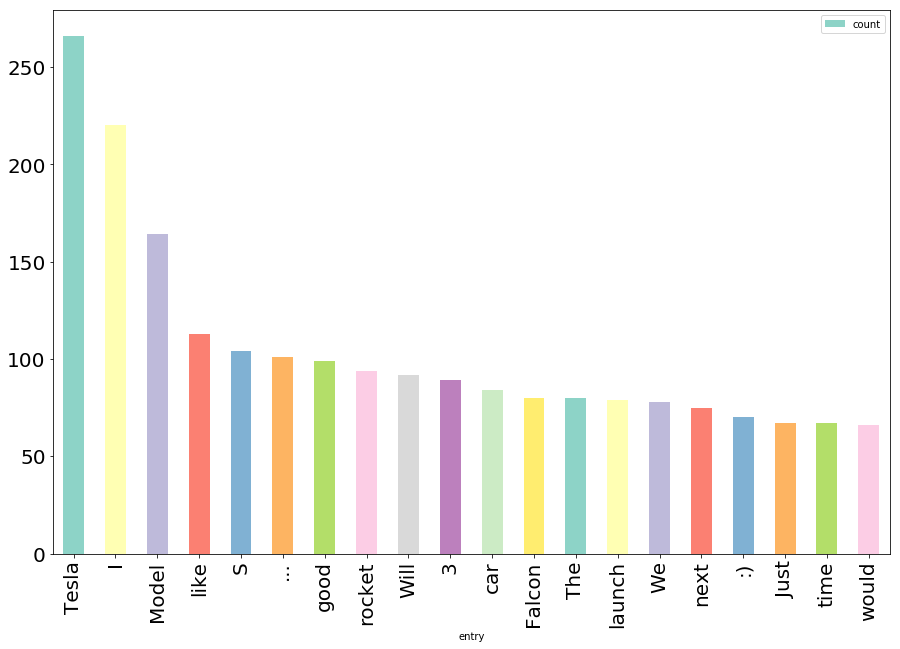
Most common 1-grams:
Tesla 266
I 220
Model 164
like 113
S 104
... 101
good 99
rocket 94
Will 92
3 89
car 84
Falcon 80
The 80
launch 79
We 78
next 75
:) 70
Just 67
time 67
would 66
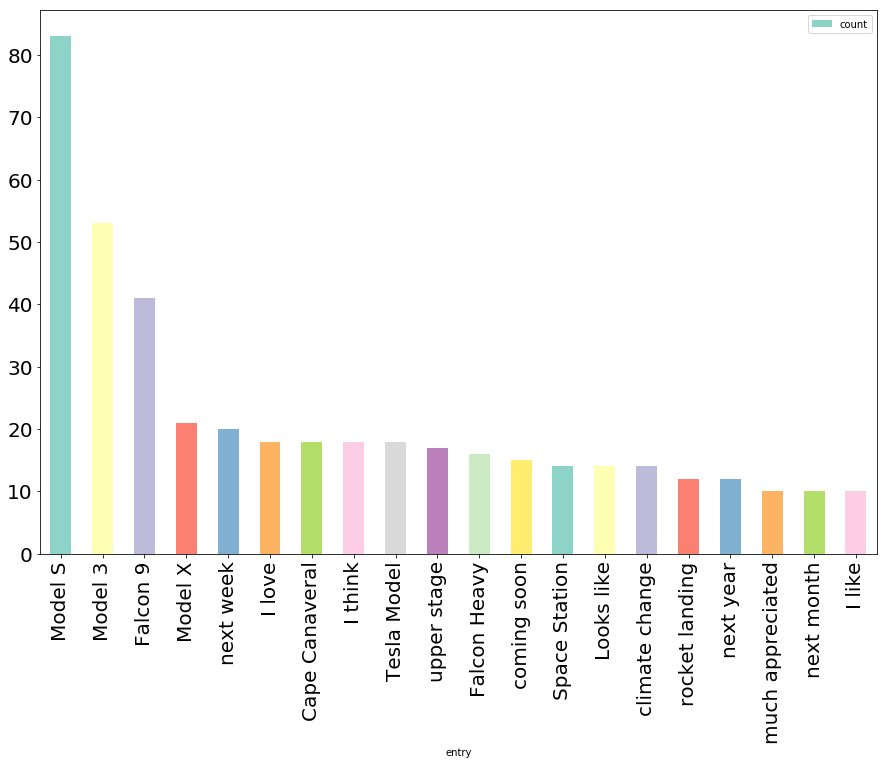
Most common 2-grams:
Model S 83
Model 3 53
Falcon 9 41
Model X 21
next week 20
I love 18
Cape Canaveral 18
I think 18
Tesla Model 18
upper stage 17
Falcon Heavy 16
coming soon 15
Space Station 14
Looks like 14
climate change 14
rocket landing 12
next year 12
much appreciated 10
next month 10
I like 10
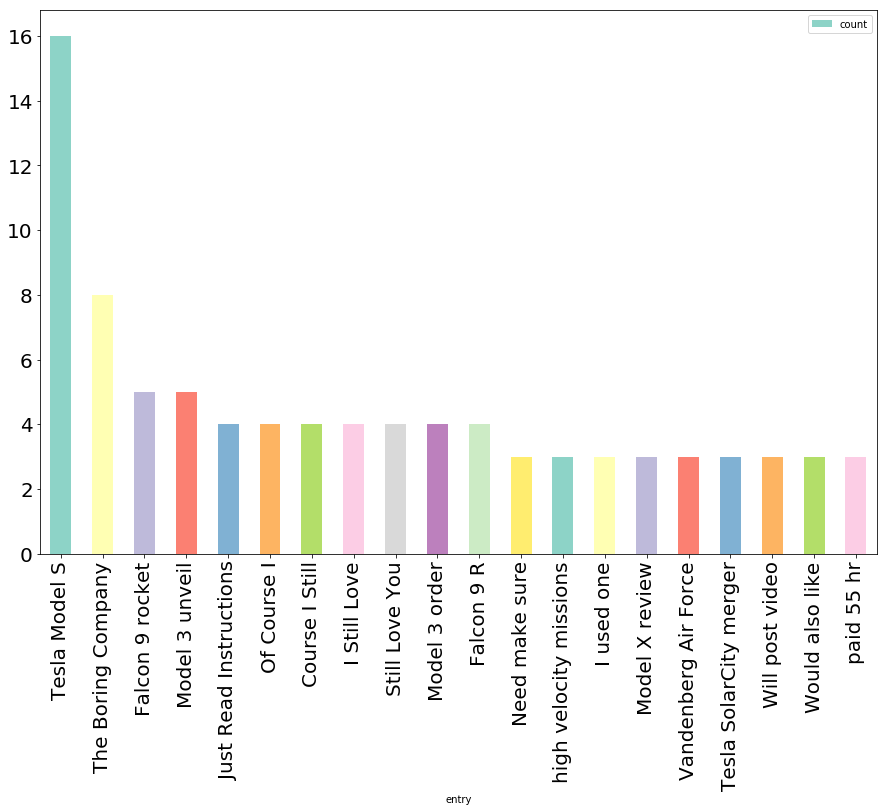
Most common 3-grams:
Tesla Model S 16
The Boring Company 8
Falcon 9 rocket 5
Model 3 unveil 5
Just Read Instructions 4
Of Course I 4
Course I Still 4
I Still Love 4
Still Love You 4
Model 3 order 4
Falcon 9 R 4
Need make sure 3
high velocity missions 3
I used one 3
Model X review 3
Vandenberg Air Force 3
Tesla SolarCity merger 3
Will post video 3
Would also like 3
paid 55 hr 3
As I hoped, bigrams and trigrams give us a lot more insight into the specific entities
that show up in Elon’s posts. We have Model S and Model 3, as well as The Boring Company
and Vandenberg Air Force (one of the rare instances where 4-grams would be more informative -
Vandenberg Air Force Base is the location in California where some of the SpaceX launches happen)
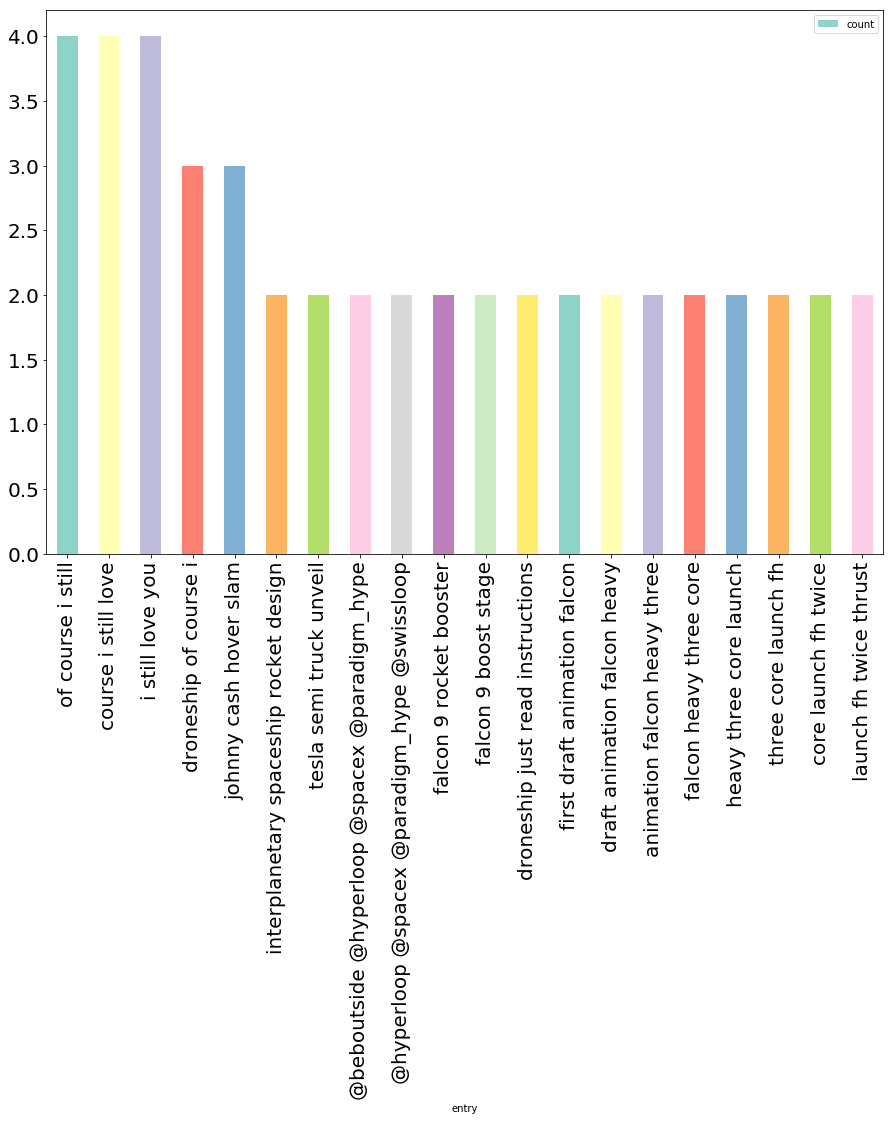
Okay okay - let’s look at 4-grams too.
Most common 4-grams:
Of Course I Still 4
Course I Still Love 4
I Still Love You 4
Interplanetary Spaceship Rocket design 2
Tesla Semi truck unveil 2
@beboutside @Hyperloop @SpaceX @paradigm_hype 2
@Hyperloop @SpaceX @paradigm_hype @swissloop 2
Falcon 9 rocket booster 2
Falcon 9 boost stage 2
First draft animation Falcon 2
draft animation Falcon Heavy 2
animation Falcon Heavy three 2
Falcon Heavy three core 2
Heavy three core launch 2
three core launch FH 2
core launch FH twice 2
launch FH twice thrust 2
FH twice thrust next 2
Our love never die 2
cars built since Oct 2
Wait, what happened to Vandenberg? This is kind of weird. Looking through this I realized I forgot the cardinal rule of Twitter Data: always lowercase everything. Elon is better than most about using proper capitalization and punctuation, but usually in topic modeling we don’t care about capital letters. Let’s see what this looks like with all lower case.
unstopped_and_depunct_and_lower = [[t.lower() for t in unstopped_and_depunct_datum] for unstopped_and_depunct_datum in tqdm(unstopped_and_depunct)]
Most common 4-grams:
of course i still 4
course i still love 4
i still love you 4
droneship of course i 3
johnny cash hover slam 3
interplanetary spaceship rocket design 2
tesla semi truck unveil 2
@beboutside @hyperloop @spacex @paradigm_hype 2
@hyperloop @spacex @paradigm_hype @swissloop 2
falcon 9 rocket booster 2
falcon 9 boost stage 2
droneship just read instructions 2
first draft animation falcon 2
draft animation falcon heavy 2
animation falcon heavy three 2
falcon heavy three core 2
heavy three core launch 2
three core launch fh 2
core launch fh twice 2
launch fh twice thrust 2
Fine, whatever. I didn’t want to know about vandenberg anyway.
Okay, now that we’ve got all of our n-gram data, let’s plot it. I’m using bar graphs because I am boring, but also because bar graphs are one of like 4 actually useful graph types in the universe. (the other two being scatter, pie and line)
I’m very sensitive to colors in graphics, something I think a lot of people overlook.
There’s a site I particularly like called ColorBrewer
created by Cynthia Brewer. She’s done a lot of research on color perception
and color blindness, and other things that it’s easy to overlook in making a good
visualization. I’m picking one of the palettes in colorbrewer2 that I think looks
nice.
import palettable
from palettable.colorbrewer.qualitative import Set3_12 as palette
And now to plot each of our n-gram top lists:
for n in ns:
data = pd.DataFrame([{"entry": " ".join(entry), "count": count} for entry, count in nGramFreqs[n].most_common(20)])
data.plot(kind="bar", x="entry", figsize=(15,10), fontsize=20, color=[palette.mpl_colors,])
Note that bar plots are currently slightly broken in Pandas
in that the color parameter doesn’t behave properly. To get around that, we wrap
the color palette in a seemingly useless outer list. Thanks
Github Issue Tracker!
NEXT: Topic Modeling